美しき国のガラパゴス・ネットスラング
「ガラケー」
かくも簡潔で語呂の良い、もはやネットスラングを超越した、広く市民権を得た言葉ですね。
「ガラケー」あるいは、ガラパゴス・ケータイとは、もちろん「グローバリズム」の潮流の中で出てきたネットスラングです。
「グローバリズム」とは特に歴史と伝統が深く豊かな我が国日本において、賛否が別れる考え方です。
音楽に国境はない、とは言いますが、それでもガラパゴス故に生まれた「J-POP」など、グローバリズムの中にあっても日本独自の優位性が発揮されているものがあります。
しかし学問の世界、特に数学やプログラミング技術は、国境がない真のグローバリズムの世界であると思います。
プログラミング技術の世界には国境はない真のグローバリズムの世界なのですが、日本のプログラミング技術の世界では、昨今「ガラパゴス」になっているようです。
少なくとも、とある珍妙なガラパゴス・ネットスラングというべきものが普及しており、その奇っ怪な状況を誰も咎めるものは居ないように、少なくとも、私には見えます。
先駆的なソフトウェア開発と根底にある哲学
あくまでグローバルなソフトウェア開発の世界では、たとえば、
という有名な言葉があります。
この言葉は、特筆性の条件を満たしているので、当然このように、
Wikipediaの項目にもなっています。
UNIX哲学とは、ソフトウェア開発に関する文化的な規範と哲学的アプローチのまとまりであり、UNIX OSの先駆的な開発者たちの経験に基づいている。
ソフトウェア開発、OSの開発が先駆的に進んだ欧米では、昔から常にその根底に位置する「哲学」が熱心に議論され語られてきました。
ソフトウェア開発、OSの開発では、「哲学」は尊重されました。リスペクトされてきました。
すべての技術の根底には「設計思想」があり「哲学」があると。
この潮流は特に欧米においては、現代にも脈々と受け継がれており、著名なハッカー、
たとえば、@substackも、自身のことを
unix philosopher (UNIX哲学者)
http://substack.net/
と称しています。
https://github.com/substack/stream-handbook
という頻繁に参照される著名記事の冒頭においてもその一端が垣間見えます。

また、
http://danieltao.com/lazy.js/
の開発者である、DanTaoは、シリコンバレーのGoogle社員ですが、彼も、
http://philosopherdeveloper.com/about.html
サイトドメインにあるとおり、
DAN TAO
the philosopher developer (哲学者の開発者)
と自身を称しており、
I’m a software developer currently residing in San Francisco. I work at Google on the Ads Review team. Previously I worked at Cardpool, and before that ThoughtWorks (and before that, an algorithmic trading company in Philadelphia that no one’s ever heard of).
I studied philosophy at Duke University, then a couple of years later went to Carnegie Mellon Silicon Valley for a graduate degree in software engineering (hence the name of this blog). In between I lived with my wife in Namibia for a year through WorldTeach, an organization that places volunteer teachers in developing countries around the world.
A disclaimer about my writing. I try to be humble, but I also form a lot of opinions over the course of my (thus far, pretty short) career. So I often write about how I think software should be developed, or how teams or even companies (especially tech companies) should operate. Bear in mind that I’ve never run my own company. It’s possible that I might like to some day; but I would never want to run a business just for the sake of running a business, so it’s also possible that I might not.
One principle I believe in quite strongly is that there’s really no place for arrogance in this world. Living in Silicon Valley, I can’t help but feel that most of us in this industry are encouraged to forget that. The culture here is one seemingly designed to inflate egos and reward self-importance. Having said that, I realize that I’m guilty of it from time to time as well. So let this page serve as my perpetual apology for ever letting my head get too big, or acting like I know what I’m talking about.
と自信の「哲学的立場と発言」について明確にしています。
これは、繰り返しとなりますが、特にソフトウェア開発、OSの開発が先駆的に進んだ欧米では、特に「哲学」が技術の根底にあるという広いコンセンサスとリスペクトの潮流にある技術者の通常のあり方だと思います。
「ポエム」と発するものたちの「体たらく」、何がしたい?
さて、もし彼らが、現在の我が国の「ガラパゴス」世界で同じ声明を出したらどうなるでしょうか?
「ポエマー」だと馬鹿にされるんですね。
たとえば、このような技術的状況にまつわる「随想」でさえ「ポエム」と「言い換えてレッテルを貼る」ものたちがいます。
念の為(揚げ足取りをあらかじめ祓うために面倒なこと)ですが「ポエム」という言葉自体は言うまでもなく中立でクリーンな言葉です。
しかし、哲学的行為を、自分自身の頭で考える行為、それを表明する行為を「侮蔑的な意図をもって」「ポエム」と愚弄するものたちがいます。
「随想」の何が悪いんでしょうか?
技術にまつわる話題で個人のオリジナルな視点を表明することの何が悪いのでしょうか?
一体何なんでしょう?この我が国の技術者たちの「体たらく」は??
逐一「ポエム」とレッテルをはり、侮辱する人は「いったいぜんたい何をやりたい」のでしょうか?
「呪詛」である「呪い」である、「怖い」から滑稽な「おことわり」「お札」を貼りまくる人たち
端的に説明しましょう。
技術記事に「ポエム」とレッテルを貼ることは、相手の言説に「呪詛」「呪い」を加えることです。
「ポエム」とレッテルを貼ることで「呪いをかける」ことができ、相手の言説に、なんとなーく嫌な雰囲気を与えることができる。
我が国の主要なプログラミング技術記事、投稿、共有サイト、
Qiitaの記事にしても、少し前から、自分の自由な考えを投稿する際に
「****ポエム」というタイトルであるとか、
記事の冒頭や最後に「*****というポエムです。」
という珍妙で滑稽な【言い訳】を書く人ばかりになりました。
なんで、自分の自由な考えを表明するのに、いちいち「ポエム」だっていう
「おことわり」を書かなければいけないんでしょうね?
「おことわり」を書かなければいけない理由とはただひとつ。「怖い」からです。
「これはポエムです」ってわざわざ、いちいち珍妙で滑稽な「おことわり」を入れる、
もっと言えば自分の記事を「まもるため」の「お札」を記事に貼り付け「なければ不安」なのは、
「怖い」からでしょ?
残念、それは「お札」ではない「呪い」である
でも残念だけど、それは「お札」じゃないんですね。
だって「呪いの言葉」が「お札」になるわけがない。
「ポエムです。」って自分自身の記事に、自分の考えに自分で呪いをかけているだけ。
「自由に自分の考えを表明する」という正当な行為にすでに「呪い」がかけられているものだから、その「呪い」を祓うために、自分で自分自身に呪いの言葉をかけなければいけない。
自虐のつもり?「ネタ」?
「自虐的」であることで、先回りして自分自身の言説を守っているつもりなのかしりませんが、
なんのことはない、低いレベルに自分自身の言説を貶め、加虐しているにすぎません。
じゃあ、あなたは自分の考えを表明するときには、
これからずっと、いちいちそういう自虐ネタとして扱うわけですか?
はい、これが自分で自分に呪いをかけた顛末なのですね。
「自由に自分の考えを表明する」という正当な行為で、文章ひとつ書くにも「呪い」の事を気にしなければいけない雰囲気が醸成されてしまっている現状に異常を感じないのは、彼らが「呪いまみれ」になってしまっているからですね。
奇っ怪で、異常な事態
あきらかに、奇っ怪で、異常な事態が進行しています。
私は、以前から「ああ、なんか異常な事態になっているな」と思っていたので、
「ポエム」だとなんだと言われようが、まったく気にせずに、
「関数型プログラミング」の「考え方」、「哲学的側面」について自分の考えを堂々と表明して投稿していました。
「関数型ポエム」そして、民族神道の精神に基づく「呪い返し」
もちろん連中からは、「関数型ポエム」という「蔑称」の「呪い」がかけられました。
そこで、今回、せっかくですからこの記事で、「呪い返し」をしてみたいと思います。
われわれ日本人は民族的に根本的には神道信者です。
聖徳太子の時代以降、学問とともに大陸から伝来した仏教が、
「神道vs仏教」の壮絶な宗教戦争の結果、勝利し、神道を圧倒しましたが、
根本では我々日本人の精神には神道が今も受け継がれています。
われわれ日本人は、お正月には初詣をすることが大好きですし、
神社で購入した、家内安全、恋愛成就、商売繁盛、交通安全、いろんなお守りを大事に携帯している人はとても多いと思います。
バチがあたる、という考え方にも馴染みは深いです。
家の宗教は密教であり、葬式は仏教の作法にのっとり粛々と行われますが、
母親の家系は神道の神主の家系です。
母親の実家には、仏壇、そして、かなりしっかりとした大きな神棚が双方別々に祀られています。
実は、私が読書の習慣があるのは、母親の家系の影響で、母親の実家の屋根裏部屋には膨大な書籍があります。
ちなみに父親の家系は、祖父は外資系の技術者(高給取りであったらしい)で、私が技術系、理系であるのは、その家系の影響です。
私は情報技術者ですが、母親の神道家系の血が流れていますから、多分、「呪い返し」の「神通力」も多少なりとはあると思います。たぶんね。
我々日本人の精神的土壌は神道であるので、「穢れ」を嫌います。
「呪われれる」ことを忌み嫌います。
「ポエム」とレッテルを貼るものたちは、同じ精神的土壌を共有するが故に、そういう、相手が忌み嫌うことを嬉々としてやっているわけですね。
相手が忌み嫌う、と理解している、ってことは、とりもなおさず、自分がやられた忌み嫌う、ってわかっているからだ。
同じ精神的土壌を共有しているから。
え?違う?じゃあ、君たち、なんでそんなしょうもないことやって嬉しいのでしょうか?
「呪い」が効力を発する精神的プロトコルを共有している自覚があるから。
精神的土壌を共有する、精神的プロトコルを共有している自覚がないならば、
「呪い」なんてなんの効力ももちません。ただの無味乾燥な言葉の羅列にすぎません。
「ポエム」と書くことにより、他者の自由な言説にたいして、「呪い」をかけるわけですが、
それが「呪い」である以上、同じように「呪い返し」をすることは極めて容易であり、
それは相手が同じ神道の精神的土壌を共有してさえおればよいわけです。
そもそも、誹謗中傷に勤しむ性向をもつ集団のメンバーはすべてもれなく他人に不当な「呪い」をかけて喜んでいるような異常な集団ですから、「呪い返し」というのは大きな効果があります。
言葉の暴力、呪いが横行するHatenaブックマークのコメント
特に、無責任な文責を負わない匿名の書き捨て、言葉の暴力、呪いが横行するHatenaブックマークのコメントを書き込むものに対して、この呪いを返します。
このエントリにたいしても、「ポエム」だと呪いのワードを書けば良いでしょう。
いくら屁理屈をこねても無駄。
それはそのまま「呪い返し」が自動的になされるようになっています。
「呪い返し」の絶対的アドバンテージの理由 それは「論理」の「宣言」にすぎない「関数」という装置だから
「呪い返し」の良い所は、「言葉の応酬」にならなくて済むところです。
「呪い返し」とは、命令形プログラミングの「手続き」あるいは「命令」ではなく、
「論理」の「宣言」にすぎません。いわば関数型プログラミングの「関数」です。
撃たれたら、逐一撃ち返すという「行為」の連続ではなく、
そこに「鏡」をポンとおくだけの、「論理」の「宣言」をしてやる。
ただそれだけです。
あとはその「鏡」が「入力」に呼応した「出力」を自動的に返します。
エネルギーはすべてその「入力」に依存しており、自身まったくエネルギーを必要としない、装置にすぎません。
やるな、やってはいけない、と咎められれば、余計やりたくなるのが、幼児的な衝動を抑えきれない彼らです。試みてもこっちが疲弊するだけ。
でも鏡を、論理的な巨大な鏡を宣言するだけなら、手間はかからない。
いくらでもやれ、それは「逐一もれなく呪い返される」ということです。
「呪い返し」とは、あくまで邪な「呪い」を撥ね返す受動者の防御行為であり、
呪い返すほうにリスクはまったくありません。
自発的に邪な動機で「呪い」を返すもの自身にたいして「自業自得」の道理を通すための術であって、「呪い返し」の「呪い返し」は原理的に成立しないからです。
人を呪わば穴ふたつ
一方で、「呪い」をかけるものには多大なリスクがあります。
「人を呪わば穴ふたつ」
この言葉を聞いたことがある人は多いでしょう。人に呪いをかけるとろくなことにはなりません。
この言葉は、まさに不当な「呪い」が「呪い返し」によってどのような顛末になるのか説明している言葉です。
実践!やってみよう!「呪い返し」
では、このエントリでは、その「ポエム」と「呪いをかける」すべての愚かな人々に呪い返しをしたいと思います。
プログラミングの世界で、「ポエム」とは、「ガラパゴス・ネットラング」であり、この言葉を優越的気分から侮蔑的な意味で、これまで用いた、そしてこれから用いるものは、まもなく必ず、世の中の侮蔑の対象となる、また周到に「ポエム」という言葉を避けながら、同じ立場で行為を支援し続ける同族に対しても、以上と同じ呪い返しの効力がある
「呪い返し」とは、論理性と正当性、つまり道理が必要とされます。
このエントリでは、すでに、その道理を説明しました。
遂に「書評」という、ごく普通の行為にさえも「レビューポエム」と自分で呪う、奇っ怪な現象が・・・
「ポエム」が「呪い」の言葉であると知っているのでしょう、
単純な書評でさえ、自身の書評にさえ「呪い」をかける(自分では防御する「お札」だと思っている)という、通常では考えにくい奇っ怪な現象が起こっています。
「書評」ひとつ書くにあたっても「いちいち【ポエム】と【自虐の呪い】を自分自身に向けてかけながら【言い訳】をせなければいけない」理由って一体どこにあるんでしょうか?
めがねをかけるんだ
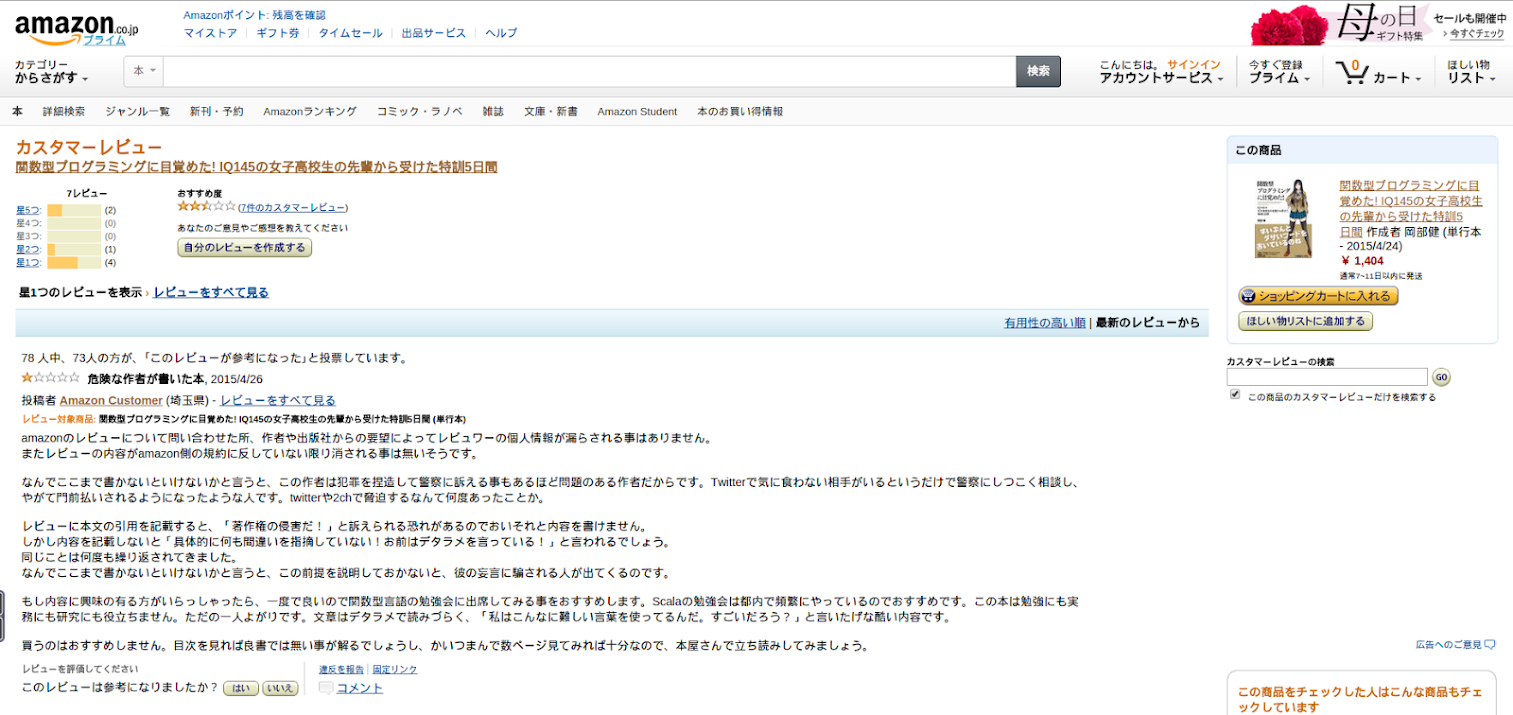
レビューポエム “関数型プログラミングに目覚めた! IQ145の女子高校生の先輩から受けた特訓5日間” を読んで
本当は立ち読みですませる気だったんですが、買わないでレビューはフェアではないかなと思い……今は後悔しています。
以上、悔しかったのでブログのネタとしてなるべくライトに感想を書きましたが、本編は読んでいて本当に苦痛だったので、僕は、みなさんにはお勧めしません。
お買い上げいただき、どうもありがとうございました。そして、同情いたします。
もちろん、最初から腐すつもりであった本に1400円も支払ったのは、とてもお気の毒ですね。お買い上げいただき、どうもありがとうございました。
わざわざレシートの写真まで貼り付けておられて、よほど悔しかったのでしょうか?
最初から腐す目的の書籍に身銭を切るというのは、さぞや屈辱的であったでしょうから、その「悔しい」お気持ちは当方も想像するに余りあります。申し訳ありません・・・
著者としてフェアに言うと、こういう最初から反発して読みにかかる、そもそも私の解説の仕方に批判的な先入観がある連中を本書では、結構露骨に批判してしまっていますから(笑)、それは「読んでいて本当に苦痛だった」でしょうね。でも、そうならそうと正直に書かなきゃ不誠実でしょう??でも、お金を払って読んでいる自分の批判を展開されるのは悔しかったことでしょう。同情いたします。
自分の立場と他の人の立場は一致などしない
でも、先入観も何もない読者にとっては、その批判の相手は自分ではないので、なんら苦痛に感じないのですよ?ただ、その連中を反面教師として「学ぶ」だけです。知的に建設的な体験をします。
自分の立場と他の人の立場は一致などしないのです。
だから自分が受けた感傷をもって、それがすなわち他者が受けるだろう感傷と一致する、と考えるのは重大な論理的誤りです。
主観的評価とは、客観的評価にはなりえない。基本ですよね。
たとえば、ここに別の方の書評があります。あなたの主観とはまるで異なるでしょう?
先入観をもたない読者による書評
『関数型プログラミングに目覚めた! IQ145の女子高校生の先輩から受けた特訓5日間』を読んだ (Persistence)
全体的に好意的で、難しい部分についても抑制的な論調の書評ですが、一部、引用させていただくと、
この本の感想を3行でまとめると
- 命令型プログラミングから関数型プログラミングへのパラダイムシフトを体験できた
- 関数型プログラミングができるまでの歴史的背景を知ることができた
- 本を読む姿勢を改めて考えさせられたパラダイムシフト
本書の前半半分は、命令形プログラミングと関数型プログラミングのパラダイムの違いを非常に分かりやすく説明されています。自分が今まで書いていた命令形プログラミングはフローを作成して機能毎に分割して作っていましたが、関数型プログラミングはフローや状態を排除し論理毎に機能を作成し、必要になった時に必要な分だけ計算する(イベント駆動)という方法を取ります。「論理」と「計算」を分けて考えるという説明はわかりやすかったです。
一方の後半半分は、FRP(関数型リアクティブプログラミング)の説明になるのですが、アリストテレス、ピタゴラス、プラトン、デカルト、などの哲学思想(これはこれで読み物としては面白かったですが)とFRPを対比させて説明が進んでいくのですが、正直最後の方はついていけなくなりました。まあこの辺は、FRPだけを説明するのはもっと簡単だけど、筆者としてはその根本的な思想を伝えたかったのだと思います。
会話形式で説明が進んでいく中でいくつものプログラミングに関する歴史が説明されており、読み物として面白かったです。例えばJavaScriptの生い立ちの話とか、命令形プログラミングから関数型プログラミングへのパラダイムシフトやの歴史、そして次のパラダイムシフトは何かなど。
「論理」と「計算」を分けて考えるという説明はわかりやすかったです。
というのは、しっかり伝わったことが確認できて、著者として書いた甲斐がありました。たいへん嬉しいです。
そして、「読み物として面白かったです」ということです。どうもありがとうございます。
「苦痛」とは程遠い感想ですね。
「先入観のない」「普通の読者」がよめば「普通に楽しめる」ように書いてあります。
「先入観のある読者」「先入観のない読者」何がどう違うのか?
きっと「呪い」のせいですよね。自分の書評にまで「呪い」をかけるのはもう重症です。その奇っ怪な様態の自覚はまるでないでしょうが。
こういう状況を「お祓い」するのが「呪い返し」であり、結果的に彼らを呪いの呪縛から救ってやること、憐れみの行為を与えてやることになります。もちろんそれは、彼らが「呪い返し」を十分受けて、十分に「禊」を終えてからの話となりますが。
【自称】関数型プログラミングコミュニティ、っていうのも「ガラパゴス」
【自称】関数型プログラミングコミュニティ、っていうのも「ガラパゴス」であることはすでに説明しました。
また、その中心的人物となる、どこかの大学の教師の言説にしても、「ガラパゴス」であることはすでに説明しました。
私は彼らからいろいろと呪いを受けましたので、当ブログのエントリにて「呪い返し」をしました。やり方は、ご覧のとおり、対象を明確に特定し、こちらの正当性を明確に説明する、という道理を通した正攻法です。「学問に王道なし」
禊
彼らには今後「禊」が必要になってくるでしょう。
「説明責任」という「禊」です。
「関数型プログラミングの勉強会」というのが、もし愚かな「ポエム」という「ガラパゴス」な呪いをかける論調のメンバーが中心であるのならば、そこでは、私の「呪い返し」を受けて、誠実な説明責任を要求する真摯な学習者、技術者が出ることでしょう。
現在のところ、いかなる「禊」もネット上に存在しないからです。
学問の場でも、誠実な説明責任の要求とともに、議論が行われるでしょう。
現在のところ、いかなる「禊」もネット上に存在しないからです。
彼らはそういう「穢れ」「禊のない状態」は嫌うんですね。
納得などしていない。ごまかしも通用しない。権威主義は多分もう通用しない。
「呪い返し」を私がもうしたから。
関数型プログラミングとオブジェクト指向のパラダイムとしての対立 国内の【自称】関数型コミュニティと海外の論調の違い
で、説明したように、「ガラパゴス」でない広く国際的な説明は、私の論調と一致しており、
一方で、「ガラパゴス」な彼らの論調は広く国際的な説明と一致しない、
ボトムラインとして、誰でも確認できるこの事態について、これはなぜなのか?これまで一切の説明はない、「禊」がないことを追求されるでしょう。